Most “AI for observability” demos start with a chatbot over logs. We cared about a less flashy question: could an agent understand our production system well enough to help operate it?
At Reducto, one customer document can pass through an API server, a queue, several workers, and multiple model calls before it turns into a response. A slow job might be waiting for capacity. It might be doing expensive inference. It might be caught in a retry path. The hard part is rarely noticing that something happened. Instead, it’s about figuring out which story is true.
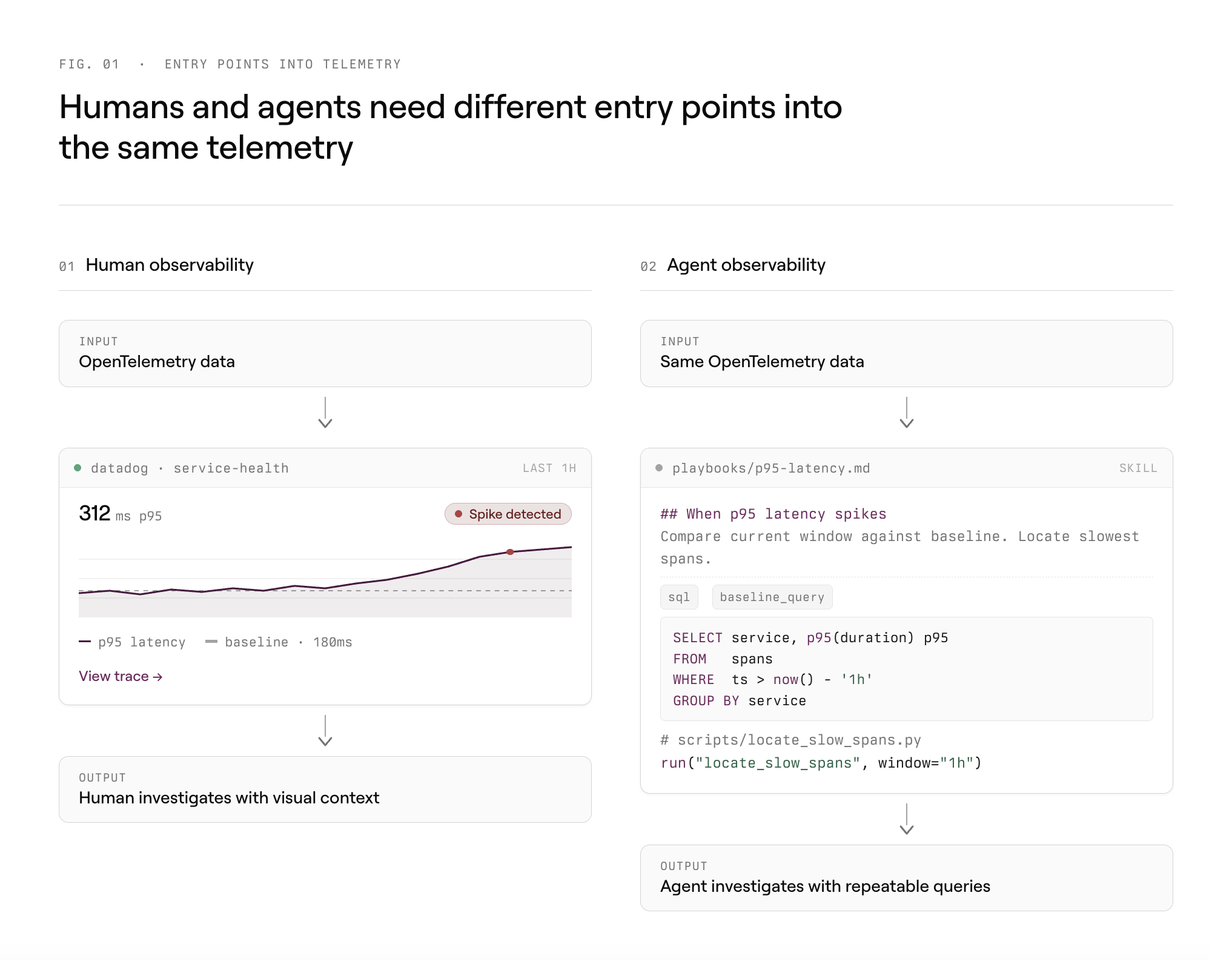
From dashboards to queries
Like many infrastructure teams, we send telemetry to Datadog. It is where our alerts fire, where dashboards live, and where on-call engineers get oriented.
As models got better at writing queries and calling tools, we started wanting a different path for agent work. Datadog is great for humans looking at the system. Agents need to ask an operational question, run follow-up queries, and keep narrowing the answer without bouncing through a dashboard API.
A queue alert
A recent queue-time alert is a good example. The alert itself was plain enough: document-processing jobs in our EU region were waiting longer than usual before a worker picked them up. The useful question was not “is the queue high?” It was “why is this queue high right now?”
To answer that, we needed to separate a capacity problem from a traffic spike, then check whether the jobs were slow after they left the queue.
An engineer can get there, but it takes a bunch of tab-hopping. You check the alert, open dashboards, look for recent deploys, read the incident channel, and then start slicing traffic to see who was actually using the system. Devin, our background agent, did that work from a playbook. It pulled the pieces together quickly enough to root cause: a burst of work hit the EU region and a recent PR had caused our normal throttling logic to fail to engage.
Making telemetry queryable
We had been using OpenTelemetry before agents were good enough to help here. It gave us the raw material: IDs, timing, spans, logs. Raw material is not enough.
The naive version is to hand an agent direct access to spans and ask it what happened. That looks impressive for a minute. Then it starts overfitting to one weird trace, missing the baseline, or inventing a story from partial evidence. Bulk trace data is too easy to misread, at least with the models we have today.
So we made queryability the product surface for agents. Datadog still matters, but it is not where we want agents to start. They need to ask lots of small questions, compare against history, and join across parts of the system without fighting dashboard APIs or rate limits. For us, that usually means SQL over tables with predictable names.
More concretely, we pipe all of our OTEL data into a ClickHouse database that agents can query in real time over the last 90 days and store long-term data in cold object storage queryable with DuckDB. OTEL Collector makes piping to these different destinations trivial!
Playbooks over dashboards
Playbooks and skills are the agent version of dashboards. A dashboard gives a human an opinionated starting point: look here first, compare against this baseline, drill in if it looks weird. A playbook does the same thing for an agent, except the interface is markdown, scripts, and repeatable query patterns.
Enterprise deployments
We are also bringing these patterns into enterprise deployments. We have made a lot of progress unifying our hosted monitoring stack, but many Reducto customers run in environments they control: on-prem, inside private networks, or across clouds with strict security and data residency requirements. The same observability ideas apply, but the shape of the deployment changes.
That is what makes the work interesting. A customer deployment still needs enough observability for agents to help with the first pass. The system also has to fit the customer’s network, cloud account, and security model instead of assuming it can look exactly like our hosted environment.
If that kind of infrastructure work sounds like fun, we are hiring for it and would love to chat with you!